Duplicate Content and SEO: Is There Really a Penalty?
There are thousands of factors that impact your website’s organic performance. One of the factors long thought to be high on Google’s list is duplicate content. Having identical or similar pages causes keyword cannibalization, reduces your domain authority and can negatively impact user experience. Luckily, duplicate content issues are often easy to resolve once you know how to find them.
What Is Duplicate Content?
Duplicate content is any text, photo or other HTML element that appears in more than one place on the internet. That includes all URLs, whether they’re pages on your site or elsewhere on the web. It’s often best to break duplicate content down into two categories:
- Internal duplicate content – More than one page on a domain has identical or similar content. This often happens when “duplicating” pages to make additional product, service or blog pages.
- External duplicate content – More than one page on multiple domains has similar content. This is usually the result of plagiarism or, in some cases, an organization replicating site content and using a new domain without redirecting users from the old domain.
Why Is Having Duplicate Content an Issue for SEO?
Duplicate content negatively impacts two audiences. Admittedly, one is an algorithm, but both search engines and site users are tripped up when your site has multiple pages with the same content.
Related: The Big, Bad List of SEO Terms You Need to Know
SEO, Duplicate Content and Google
You may have heard of Google’s duplicate content penalty, wherein Google actively penalizes sites with duplicate content issues. There’s good news; that’s a myth. The bad news? It’s still bad. Search engines like Google won’t know which page to index, which page should rank for organic search results, or which duplicate page URL to attribute page authority and link equity to.
For site owners, it’s important to remember that Google avoids showing more than one version of your content on the SERP. Duplicate content reduces the value of all the duplicated pages, not just the newest version.
How to Find Duplicate Content and Fix It
It’s important to identify both internal and external duplicate content issues. It’s usually best to dig into internal duplicates first because you’ll be able to take action yourself to resolve the problem.
Use Site Search
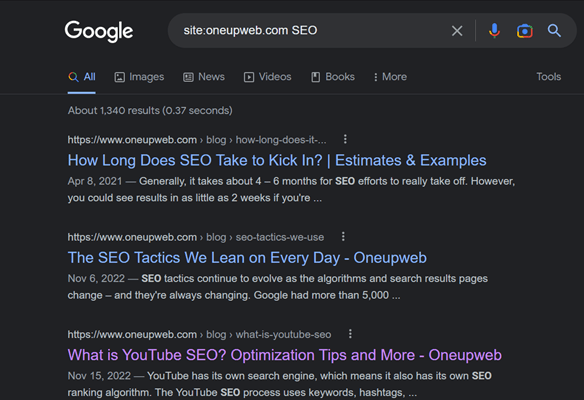
You can quickly find similar or duplicate content using a simple site search. In a Google search bar, type in site: yourdomain.com and then a keyword, such as:
site:oneupweb.com SEO
This will return only results from your domain and include any URLs that contain the keyword. Using a site search is best for longer tail keywords; as you can see, a short-term keyword on a topic you cover extensively will return a lot of results!
Use a Dedicated Tool
We use Screaming Frog for most of our in-depth site crawling work. This paid tool includes a handy duplicate content tool that identifies all troublesome pages and other SEO optimization opportunities like duplicate page titles, meta descriptions and more.
You can also use a free online duplicate site checker like Siteliner. It will analyze up to 250 pages of your domain for free. Depending on the size of your site, this might be all you need, or it can offer up a snapshot of duplicate content out of this sample size.
How to Avoid Duplicate Content in the First Place
You can create duplicate content accidentally. As much as 29% of all web content could be considered duplicate.
URL variations – Any URL variation, including those containing click tracking or filter parameters, can contribute to duplicate content problems. The addition of these code snippets impacts both the original URL and any other URL variations. Check out the following URLs:
oneupweb.com/blog/duplicate-content?#texthow
and
oneupweb.com/blog/duplicate-content?utm_source=fb&utm_medium=feed&utm_campaign=bedliners&utm_id
Both URLs refer to the same page and could cause that content to be considered duplicate. Luckily, many CMSs include tools to automatically canonicalize these types of variants to the main version of a page. (See details about canonical meta tags below!)
HTTP and HTTPS pages – Some domains include both non-secure HTTP and secure HTTPS protocols. If both page versions are live, search engines will consider it duplicate content.
Copied or reproduced content – Many ecommerce sites struggle with duplicate content if they include product descriptions on multiple pages. Using “pre-packaged” product descriptions can also result in duplicate content issues, with multiple sites displaying identical copy pulled from a centralized catalog provided by the distributor or manufacturer.
Fixing Duplicate Content Problems
If multiple versions of a page must continue to co-exist, as is often the case on ecommerce sites with multiple product variation URLs, you’ll need to help the URLs play nice with search engines.
But if the duplicate content is somewhat accidental and there’s truly just one primary version of a page, then resolving duplicate content issues comes down to pointing users and search engines to the right URL. In most cases, the right URL is the most recent, informative and robust page; consider analyzing each page version to see which ranks for the most organic keywords. In most cases, this will also be the URL that captures the most organic sessions.
Once you know where to point search engines, here’s how to fix duplicate content.
Delete Pages and Use 301 Redirects
Use this method when it’s okay to totally remove variants of a page because there’s only one true primary version.
Delete the page(s) that you don’t need, and then 301 redirect its URL to the “right” primary URL. Most Content Management Systems (CMS) offer a redirection tool. In WordPress, log in to your dashboard, go to Tools and select “Redirection.”
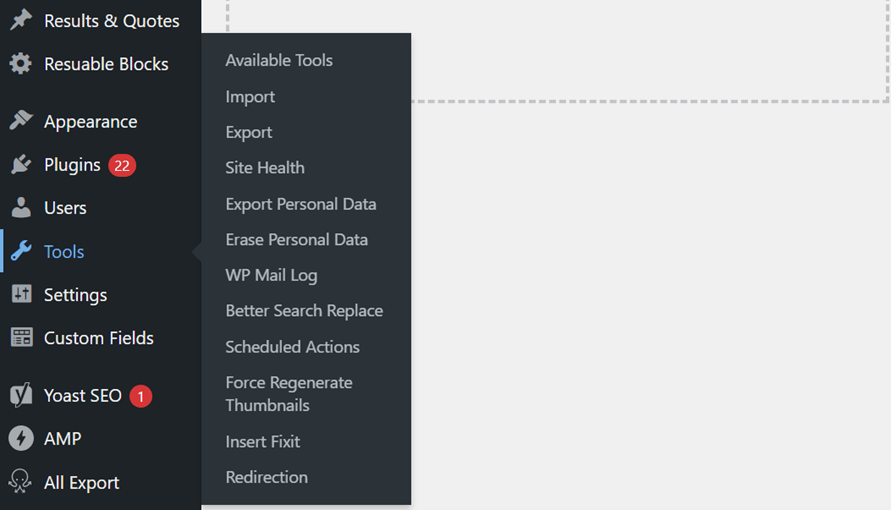
If you really want to do this cleanly, there’s a final step: Crawl your site to check for internal links that point to the variant pages that you just deleted. Update those links to point to the primary URL.
Rewrite Content
Use this method when the multiple variants of a page have the potential to be unique with individual SEO value. For example, this is ideal when you have three blogs that are too similar to each other but have potential to be further differentiated. It’s also a perfect method for a multi-location business with duplicate location pages.
The method is pretty self-explanatory: Make the content unique instead of duplicate. This includes the HTML text, the keyword strategy, the images, and any videos.
Apply Canonical Tags to Variants
Use this method when multiple variants of one page must keep co-existing, such as ecommerce product variants, “print” versions of pages, and URLs with tracking parameters.
Also known as rel=”canonical,” a canonical tag is a meta tag (a piece of code) that can be added to any webpage. Implementing the rel=”canonical” tag is like slipping a note to search engines that says, “Hey, this page exists, but you should really give credit to the OC (original content) over there.”
Add Self-Referential Canonical Tags to Pages
If you’re putting out great work, it’s only a matter of time until scrapers try to steal it. Site scrapers take content from other websites to use on their domains. This is the most common form of external duplicate content, but it’s easy to fight. Simply add a canonical tag to all pages that references the same page’s URL. This is often enough to deter scrapers, and if they do port over your entire code, the tag will ensure your URL gets credit as the source.
Let Us Do the Duplicate Digging
A Technical Site Audit from Oneupweb is an excellent way to identify common issues like duplicate content. Our SEO experts dive deep into your domain to identify and prioritize tweaks that will make your website perform perfectly. To get the most out of your digital assets, get in touch or call 231-922-9977 today to get started.
